


(测试版) BERT动态量化¶
Created On: Dec 06, 2019 | Last Updated: Jan 23, 2025 | Last Verified: Nov 05, 2024
小技巧
为了充分利用此教程,我们建议使用此`Colab版本 <https://colab.research.google.com/github/pytorch/tutorials/blob/gh-pages/_downloads/dynamic_quantization_bert_tutorial.ipynb>`_。这样可以让您试验下面所提供的信息。
作者: 黄建宇
编辑: Jessica Lin
介绍¶
在本教程中,我们将对BERT模型应用动态量化,紧跟`HuggingFace Transformers示例 <https://github.com/huggingface/transformers>`_中的BERT模型。通过这次循序渐进的旅程,我们希望展示如何将像BERT这样著名的顶尖模型转换为动态量化模型。
BERT,或双向嵌入表示的Transformer,是一种预训练语言表示的新方法,它在许多流行的自然语言处理(NLP)任务(如问答、文本分类等)上取得了最先进的准确性结果。原始论文可以在`此处 <https://arxiv.org/pdf/1810.04805.pdf>`_找到。
PyTorch中的动态量化支持将浮点模型转换为具有静态int8或float16权重数据类型和动态激活量化的量化模型。激活是动态量化到int8的(按批次),而权重量化到int8。在PyTorch中,我们有`torch.quantization.quantize_dynamic API <https://pytorch.org/docs/stable/quantization.html#torch.quantization.quantize_dynamic>`_,其替换指定模块为动态权重量化版本并输出量化模型。
我们展示了在通用语言理解评估基准`(GLUE) <https://gluebenchmark.com/>`_中的`微软研究复述语料库(MRPC)任务 <https://www.microsoft.com/en-us/download/details.aspx?id=52398>`_的准确性和推理性能结果。MRPC(Dolan和Brockett,2005)是一个自动从在线新闻来源中提取的句子对语料库,并由人工注释句子对是否语义等价。由于类别不平衡(68%为正,32%为负),我们遵循常见做法并报告`F1分数 <https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html>`_。MRPC是语言对分类的常见NLP任务,见下方。
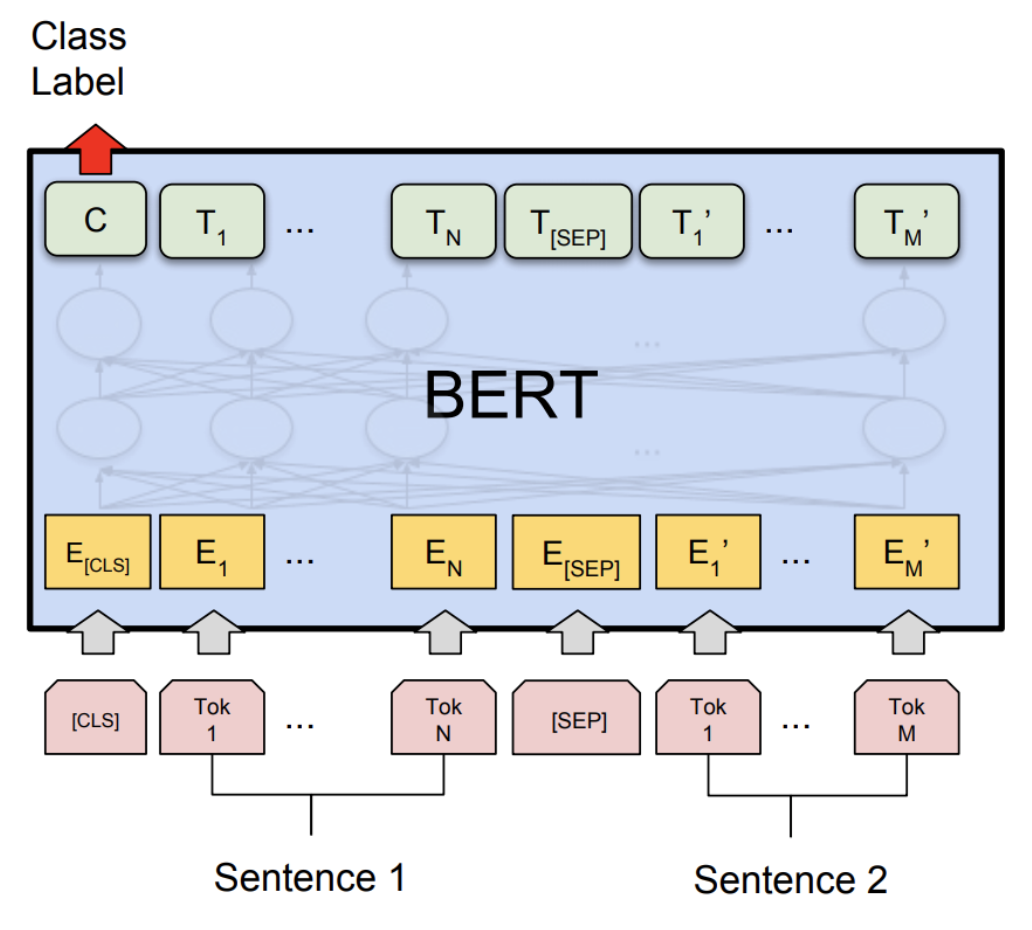
1. 设置¶
1.1 安装PyTorch和HuggingFace Transformers¶
开始本教程之前,请首先遵循PyTorch 安装说明 <https://github.com/pytorch/pytorch/#installation>`_和HuggingFace Github Repo `安装说明。此外,我们还安装`scikit-learn <https://github.com/scikit-learn/scikit-learn>`_包,因为我们将重用其内置的F1分数计算帮助函数。
pip install sklearn
pip install transformers==4.29.2
由于我们将使用PyTorch的测试版部分,建议安装最新版本的torch和torchvision。您可以在`此处 <https://pytorch.org/get-started/locally/>`_找到本地安装的最新说明。例如,在Mac上安装:
yes y | pip uninstall torch torchvision
yes y | pip install --pre torch -f https://download.pytorch.org/whl/nightly/cu101/torch_nightly.html
1.2 导入必要的模块¶
在这一步,我们导入本教程所需的Python模块。
import logging
import numpy as np
import os
import random
import sys
import time
import torch
from argparse import Namespace
from torch.utils.data import (DataLoader, RandomSampler, SequentialSampler,
TensorDataset)
from tqdm import tqdm
from transformers import (BertConfig, BertForSequenceClassification, BertTokenizer,)
from transformers import glue_compute_metrics as compute_metrics
from transformers import glue_output_modes as output_modes
from transformers import glue_processors as processors
from transformers import glue_convert_examples_to_features as convert_examples_to_features
# Setup logging
logger = logging.getLogger(__name__)
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt = '%m/%d/%Y %H:%M:%S',
level = logging.WARN)
logging.getLogger("transformers.modeling_utils").setLevel(
logging.WARN) # Reduce logging
print(torch.__version__)
我们设置线程数以比较FP32和INT8性能之间的单线程性能。在本教程末尾,用户可以通过使用合适的并行后端构建PyTorch来设置其他线程数。
torch.set_num_threads(1)
print(torch.__config__.parallel_info())
1.3 学习关于帮助函数的信息¶
transformers库中内置了帮助函数。我们主要使用以下帮助函数:一个用于将文本示例转换为特征向量;另一个用于测量预测结果的F1分数。
`glue_convert_examples_to_features <https://github.com/huggingface/transformers/blob/main/src/transformers/data/datasets/glue.py>`_函数将文本转换为输入特征:
对输入序列进行标记化;
在开头插入[CLS];
在第一句和第二句之间插入[SEP],并在末尾插入;
生成token type ids以指示标记属于第一序列还是第二序列。
glue_compute_metrics 函数包含了计算指标的功能,其中包括 F1分数。F1分数可以被解释为精确率和召回率的加权平均值,当F1分数达到1时效果最好,达到0时效果最差。精确率和召回率对F1分数的相对贡献是相等的。
F1分数的计算公式为:
2. 微调BERT模型¶
BERT的核心理念是预训练语言表示,然后在广泛的任务上使用最少的任务相关参数对深度双向表示进行微调,从而实现最先进的成果。在本教程中,我们将专注于使用预训练的BERT模型进行微调,以分类MRPC任务中语义等同的句子对。
为MRPC任务微调预训练的BERT模型(HuggingFace transformers中的``bert-base-uncased``模型),可以参考 examples 中的指令:
export GLUE_DIR=./glue_data
export TASK_NAME=MRPC
export OUT_DIR=./$TASK_NAME/
python ./run_glue.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $GLUE_DIR/$TASK_NAME \
--max_seq_length 128 \
--per_gpu_eval_batch_size=8 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--save_steps 100000 \
--output_dir $OUT_DIR
我们提供了为MRPC任务微调的BERT模型 下载链接。为了节省时间,您可以直接将该模型文件(约400 MB)下载到本地文件夹 $OUT_DIR。
2.1 设置全局配置¶
在动态量化前后评估微调的BERT模型时,我们设置全局配置。
configs = Namespace()
# The output directory for the fine-tuned model, $OUT_DIR.
configs.output_dir = "./MRPC/"
# The data directory for the MRPC task in the GLUE benchmark, $GLUE_DIR/$TASK_NAME.
configs.data_dir = "./glue_data/MRPC"
# The model name or path for the pre-trained model.
configs.model_name_or_path = "bert-base-uncased"
# The maximum length of an input sequence
configs.max_seq_length = 128
# Prepare GLUE task.
configs.task_name = "MRPC".lower()
configs.processor = processors[configs.task_name]()
configs.output_mode = output_modes[configs.task_name]
configs.label_list = configs.processor.get_labels()
configs.model_type = "bert".lower()
configs.do_lower_case = True
# Set the device, batch size, topology, and caching flags.
configs.device = "cpu"
configs.per_gpu_eval_batch_size = 8
configs.n_gpu = 0
configs.local_rank = -1
configs.overwrite_cache = False
# Set random seed for reproducibility.
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(42)
2.2 加载微调的BERT模型¶
我们从 configs.output_dir 中加载分词器和微调的BERT序列分类模型(FP32)。
tokenizer = BertTokenizer.from_pretrained(
configs.output_dir, do_lower_case=configs.do_lower_case)
model = BertForSequenceClassification.from_pretrained(configs.output_dir)
model.to(configs.device)
2.3 定义分词和评估函数¶
我们从 HuggingFace 中复用了分词和评估函数。
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
def evaluate(args, model, tokenizer, prefix=""):
# Loop to handle MNLI double evaluation (matched, mis-matched)
eval_task_names = ("mnli", "mnli-mm") if args.task_name == "mnli" else (args.task_name,)
eval_outputs_dirs = (args.output_dir, args.output_dir + '-MM') if args.task_name == "mnli" else (args.output_dir,)
results = {}
for eval_task, eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
eval_dataset = load_and_cache_examples(args, eval_task, tokenizer, evaluate=True)
if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
os.makedirs(eval_output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(eval_dataset) if args.local_rank == -1 else DistributedSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu eval
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[3]}
if args.model_type != 'distilbert':
inputs['token_type_ids'] = batch[2] if args.model_type in ['bert', 'xlnet'] else None # XLM, DistilBERT and RoBERTa don't use segment_ids
outputs = model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
if args.output_mode == "classification":
preds = np.argmax(preds, axis=1)
elif args.output_mode == "regression":
preds = np.squeeze(preds)
result = compute_metrics(eval_task, preds, out_label_ids)
results.update(result)
output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return results
def load_and_cache_examples(args, task, tokenizer, evaluate=False):
if args.local_rank not in [-1, 0] and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
processor = processors[task]()
output_mode = output_modes[task]
# Load data features from cache or dataset file
cached_features_file = os.path.join(args.data_dir, 'cached_{}_{}_{}_{}'.format(
'dev' if evaluate else 'train',
list(filter(None, args.model_name_or_path.split('/'))).pop(),
str(args.max_seq_length),
str(task)))
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
label_list = processor.get_labels()
if task in ['mnli', 'mnli-mm'] and args.model_type in ['roberta']:
# HACK(label indices are swapped in RoBERTa pretrained model)
label_list[1], label_list[2] = label_list[2], label_list[1]
examples = processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
features = convert_examples_to_features(examples,
tokenizer,
label_list=label_list,
max_length=args.max_seq_length,
output_mode=output_mode,
pad_on_left=bool(args.model_type in ['xlnet']), # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4 if args.model_type in ['xlnet'] else 0,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
if args.local_rank == 0 and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
if output_mode == "classification":
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
elif output_mode == "regression":
all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
3. 应用动态量化¶
我们调用 torch.quantization.quantize_dynamic 对HuggingFace BERT模型应用动态量化。具体来说,
我们指定希望对模型中的torch.nn.Linear模块进行量化;
我们指定希望将权重转换为量化的int8值。
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
print(quantized_model)
3.1 检查模型大小¶
首先检查模型大小。我们可以观察到模型大小显著减少(FP32总大小:438 MB;INT8总大小:181 MB):
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(model)
print_size_of_model(quantized_model)
本教程中使用的BERT模型(bert-base-uncased)的词汇表大小为30522。嵌入大小为768,总词嵌入表大小约为 ~ 4(字节/FP32) * 30522 * 768 = 90 MB。因此,借助量化,非嵌入表部分的模型大小从350 MB(FP32模型)减少到90 MB(INT8模型)。
3.2 评估推理准确性和速度¶
接下来,我们比较原始FP32模型与动态量化后INT8模型之间的推理时间以及评估准确性。
def time_model_evaluation(model, configs, tokenizer):
eval_start_time = time.time()
result = evaluate(configs, model, tokenizer, prefix="")
eval_end_time = time.time()
eval_duration_time = eval_end_time - eval_start_time
print(result)
print("Evaluate total time (seconds): {0:.1f}".format(eval_duration_time))
# Evaluate the original FP32 BERT model
time_model_evaluation(model, configs, tokenizer)
# Evaluate the INT8 BERT model after the dynamic quantization
time_model_evaluation(quantized_model, configs, tokenizer)
在MacBook Pro本地运行测试时,无量化情况下,运行MRPC数据集中所有408个样本的推理大约需要160秒,而进行量化后仅需约90秒。我们总结了在MacBook Pro上运行量化BERT模型推理的结果如下:
| Prec | F1 score | Model Size | 1 thread | 4 threads |
| FP32 | 0.9019 | 438 MB | 160 sec | 85 sec |
| INT8 | 0.902 | 181 MB | 90 sec | 46 sec |
在MRPC任务中,对微调BERT模型应用后训练动态量化后,我们的F1分数准确率下降了0.6%。作为比较,在 最近的一篇论文 (表1)中,通过应用后训练动态量化实现了0.8788,通过应用量化感知训练实现了0.8956。主要区别在于我们在PyTorch中支持非对称量化,而论文中仅支持对称量化。
注意,在本教程中,我们将线程数量设置为1,以进行单线程比较。我们还支持这些量化INT8操作符的内操作并行化。用户现在可以通过 torch.set_num_threads(N) (N``是内操作并行化线程数)设置多线程。启用内操作并行化支持的一个前提要求,是使用正确的 `后端 <https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html#build-options>`_ 构建PyTorch,例如OpenMP、Native或TBB。您可以使用 ``torch.__config__.parallel_info() 检查并行化设置。在同一台MacBook Pro上使用PyTorch和用于并行化的Native后端,我们可以得到大约46秒的MRPC数据集评估处理时间。
3.3 序列化量化模型¶
我们可以在跟踪模型后使用 torch.jit.save 序列化并保存量化模型以供未来使用。
def ids_tensor(shape, vocab_size):
# Creates a random int32 tensor of the shape within the vocab size
return torch.randint(0, vocab_size, shape=shape, dtype=torch.int, device='cpu')
input_ids = ids_tensor([8, 128], 2)
token_type_ids = ids_tensor([8, 128], 2)
attention_mask = ids_tensor([8, 128], vocab_size=2)
dummy_input = (input_ids, attention_mask, token_type_ids)
traced_model = torch.jit.trace(quantized_model, dummy_input)
torch.jit.save(traced_model, "bert_traced_eager_quant.pt")
加载量化模型时,我们可以使用 torch.jit.load
loaded_quantized_model = torch.jit.load("bert_traced_eager_quant.pt")
参考文献¶
[1] J.Devlin, M. Chang, K. Lee和K. Toutanova,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)。
[3] O. Zafrir, G. Boudoukh, P. Izsak和M. Wasserblat (2019)。Q8BERT: Quantized 8bit BERT。
