


备注
点击 这里 下载完整示例代码
使用基于 PyTorch 的 USB 进行半监督学习¶
Created On: Dec 07, 2023 | Last Updated: Mar 07, 2024 | Last Verified: Not Verified
作者:Hao Chen
统一的半监督学习基准 (USB) 是一个基于 PyTorch 构建的半监督学习 (SSL) 框架。基于 PyTorch 提供的数据集和模块,USB 成为一个灵活、模块化且易于使用的半监督学习框架。它支持多种半监督学习算法,包括 FixMatch、FreeMatch、DeFixMatch、SoftMatch 等,还支持各种不平衡的半监督学习算法。USB 包含了计算机视觉、自然语言处理和语音处理等不同数据集的基准结果。
本教程将引导你了解 USB 的基本用法。让我们首先在 CIFAR-10 数据集上使用预训练模型 Vision Transformers (ViT) 训练一个 FreeMatch/SoftMatch 模型!同时,我们会展示如何轻松切换到其他半监督算法,或在不平衡数据集上进行训练。
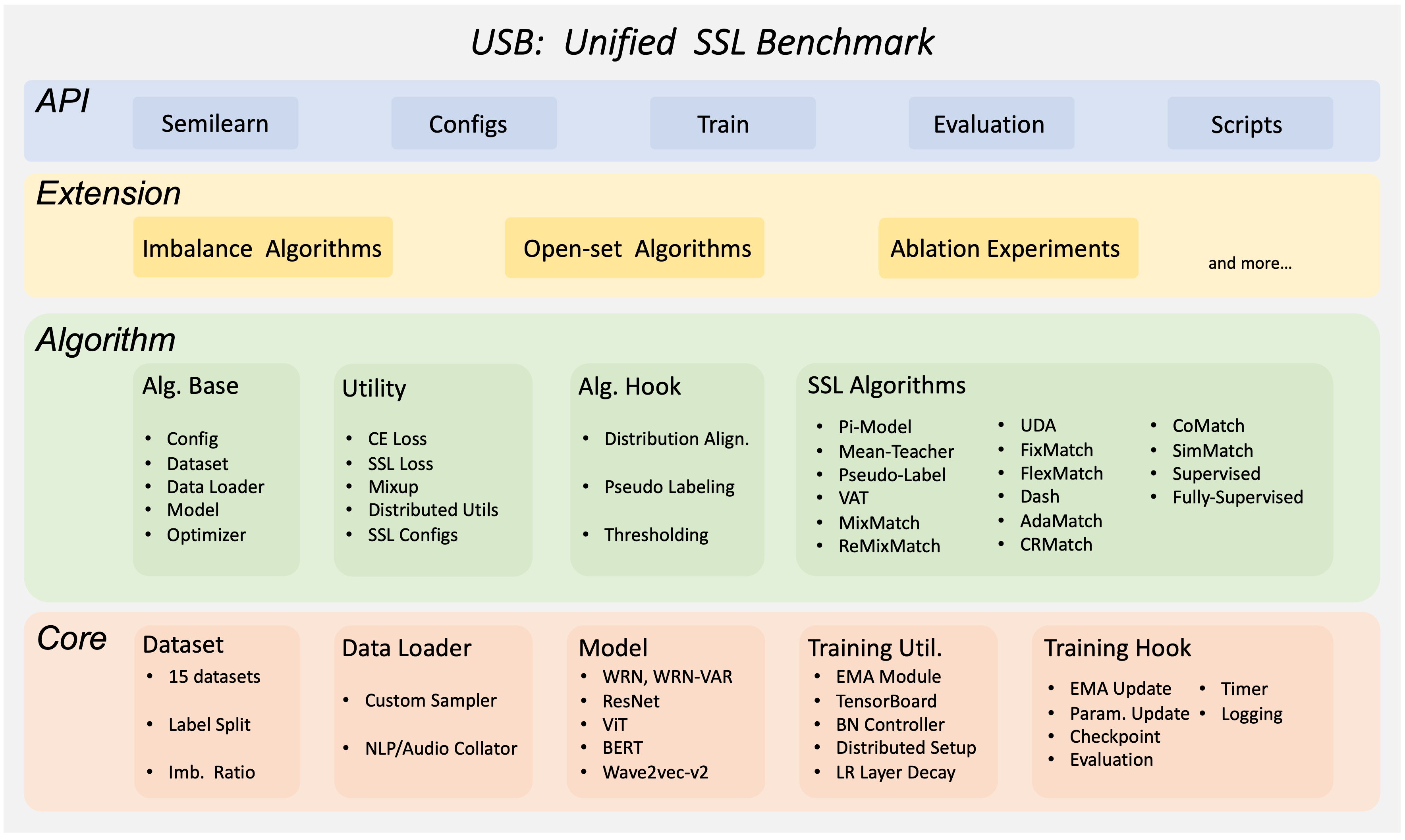
半监督学习中的 FreeMatch 和 SoftMatch 简介¶
在此,我们简要介绍 FreeMatch 和 SoftMatch。首先,我们介绍一款著名的半监督学习基线框架 FixMatch。FixMatch 是一个非常简单的半监督学习框架,通过强增强生成未标记数据的伪标签。它采用置信度阈值策略,根据固定阈值过滤低置信度的伪标签。而 FreeMatch 和 SoftMatch 是基于 FixMatch 的两种改进算法。FreeMatch 提出了自适应阈值策略来替代 FixMatch 的固定阈值策略,自适应阈值根据模型在每个类别上的学习状态逐步提高阈值。SoftMatch 将置信度阈值的思想吸收为一种权重机制,提出了一种高斯权重机制,克服伪标签的数量与质量权衡问题。在本教程中,我们将使用 USB 训练 FreeMatch 和 SoftMatch。
使用 USB 在 CIFAR-10 上训练仅含 40 个标签的 FreeMatch/SoftMatch¶
USB 易于使用和扩展,对于小团队来说是负担得起的,同时也全面支持 SSL 算法的开发和评估。USB 提供了基于一致性正则化的 14 种 SSL 算法的实现,涵盖来自计算机视觉、自然语言处理和音频领域的 15 个评估任务。它采用模块化设计,使用户可以通过添加新算法和任务轻松扩展包。它还提供了 Python API,以便更轻松地适配不同的 SSL 算法到新的数据上。
现在,让我们使用 USB 在 CIFAR-10 上训练 FreeMatch 和 SoftMatch。首先,我们需要安装 USB 包 semilearn 并导入 USB 的必要 API 功能。如果你在 Google Colab 中运行,请通过运行 !pip install semilearn 安装 semilearn。
以下是我们将从 semilearn 使用的函数列表:
get_dataset用于加载数据集,这里我们使用 CIFAR-10get_data_loader用于创建训练(有标签和无标签)和测试数据
加载器,其中训练无标签加载器将同时提供未标记数据的强增强和弱增强 - get_net_builder 用于创建模型,这里我们使用预训练 ViT - get_algorithm 用于创建半监督学习算法,这里我们使用 FreeMatch 和 SoftMatch - get_config:获取算法的默认配置 - Trainer:一个 Trainer 类,用于在数据集上训练和评估算法
请注意,使用 semilearn 包训练需要启用 CUDA 后端。有关在 Google Colab 中启用 CUDA 的说明,请参见 Enabling CUDA in Google Colab。
import semilearn
from semilearn import get_dataset, get_data_loader, get_net_builder, get_algorithm, get_config, Trainer
引入必要函数后,我们首先设置算法的超参数。
config = {
'algorithm': 'freematch',
'net': 'vit_tiny_patch2_32',
'use_pretrain': True,
'pretrain_path': 'https://github.com/microsoft/Semi-supervised-learning/releases/download/v.0.0.0/vit_tiny_patch2_32_mlp_im_1k_32.pth',
# optimization configs
'epoch': 1,
'num_train_iter': 500,
'num_eval_iter': 500,
'num_log_iter': 50,
'optim': 'AdamW',
'lr': 5e-4,
'layer_decay': 0.5,
'batch_size': 16,
'eval_batch_size': 16,
# dataset configs
'dataset': 'cifar10',
'num_labels': 40,
'num_classes': 10,
'img_size': 32,
'crop_ratio': 0.875,
'data_dir': './data',
'ulb_samples_per_class': None,
# algorithm specific configs
'hard_label': True,
'T': 0.5,
'ema_p': 0.999,
'ent_loss_ratio': 0.001,
'uratio': 2,
'ulb_loss_ratio': 1.0,
# device configs
'gpu': 0,
'world_size': 1,
'distributed': False,
"num_workers": 4,
}
config = get_config(config)
然后,我们加载数据集,并为训练和测试创建数据加载器。接着,我们指定要使用的模型和算法。
dataset_dict = get_dataset(config, config.algorithm, config.dataset, config.num_labels, config.num_classes, data_dir=config.data_dir, include_lb_to_ulb=config.include_lb_to_ulb)
train_lb_loader = get_data_loader(config, dataset_dict['train_lb'], config.batch_size)
train_ulb_loader = get_data_loader(config, dataset_dict['train_ulb'], int(config.batch_size * config.uratio))
eval_loader = get_data_loader(config, dataset_dict['eval'], config.eval_batch_size)
algorithm = get_algorithm(config, get_net_builder(config.net, from_name=False), tb_log=None, logger=None)
现在可以开始在 CIFAR-10 上训练仅含 40 个标签的算法了。我们训练 500 次迭代,并每 500 次评估一次。
trainer = Trainer(config, algorithm)
trainer.fit(train_lb_loader, train_ulb_loader, eval_loader)
最后,让我们在验证集上评估训练好的模型。经过 500 次迭代训练,仅用 CIFAR-10 上的 40 个标签,FreeMatch 模型在验证集上获得大约 87% 的准确率。
trainer.evaluate(eval_loader)
使用 USB 在不平衡的 CIFAR-10 上训练带有特定不平衡算法的 SoftMatch¶
现在假设我们有 CIFAR-10 的不平衡有标签数据集和无标签数据集,希望训练一个 SoftMatch 模型。在这种情况下,我们通过将 lb_imb_ratio 和 ulb_imb_ratio 设置为 10 来创建不平衡有标签和无标签的 CIFAR-10 数据集。此外,我们将 algorithm 替换为 softmatch,并将 imbalanced 设置为 True。
config = {
'algorithm': 'softmatch',
'net': 'vit_tiny_patch2_32',
'use_pretrain': True,
'pretrain_path': 'https://github.com/microsoft/Semi-supervised-learning/releases/download/v.0.0.0/vit_tiny_patch2_32_mlp_im_1k_32.pth',
# optimization configs
'epoch': 1,
'num_train_iter': 500,
'num_eval_iter': 500,
'num_log_iter': 50,
'optim': 'AdamW',
'lr': 5e-4,
'layer_decay': 0.5,
'batch_size': 16,
'eval_batch_size': 16,
# dataset configs
'dataset': 'cifar10',
'num_labels': 1500,
'num_classes': 10,
'img_size': 32,
'crop_ratio': 0.875,
'data_dir': './data',
'ulb_samples_per_class': None,
'lb_imb_ratio': 10,
'ulb_imb_ratio': 10,
'ulb_num_labels': 3000,
# algorithm specific configs
'hard_label': True,
'T': 0.5,
'ema_p': 0.999,
'ent_loss_ratio': 0.001,
'uratio': 2,
'ulb_loss_ratio': 1.0,
# device configs
'gpu': 0,
'world_size': 1,
'distributed': False,
"num_workers": 4,
}
config = get_config(config)
接着,我们重新加载数据集,并为训练和测试创建数据加载器。然后,我们指定要使用的模型和算法。
dataset_dict = get_dataset(config, config.algorithm, config.dataset, config.num_labels, config.num_classes, data_dir=config.data_dir, include_lb_to_ulb=config.include_lb_to_ulb)
train_lb_loader = get_data_loader(config, dataset_dict['train_lb'], config.batch_size)
train_ulb_loader = get_data_loader(config, dataset_dict['train_ulb'], int(config.batch_size * config.uratio))
eval_loader = get_data_loader(config, dataset_dict['eval'], config.eval_batch_size)
algorithm = get_algorithm(config, get_net_builder(config.net, from_name=False), tb_log=None, logger=None)
现在可以开始在 CIFAR-10 上训练仅含 40 个标签的算法了。我们训练 500 次迭代,并每 500 次评估一次。
trainer = Trainer(config, algorithm)
trainer.fit(train_lb_loader, train_ulb_loader, eval_loader)
最后,让我们在验证集上评估训练好的模型。
trainer.evaluate(eval_loader)
参考文献: - [1] USB: https://github.com/microsoft/Semi-supervised-learning - [2] Kihyuk Sohn 等. FixMatch: 使用一致性和置信度简化半监督学习 - [3] Yidong Wang 等. FreeMatch: 为半监督学习提供自适应阈值 - [4] Hao Chen 等. SoftMatch: 解决半监督学习中的数量-质量权衡问题
